Kubernetes运维-Ceph分布式存储CSI对接实战指南

Kubernetes运维-Ceph分布式存储CSI对接实战指南
王先森Ceph简介
Ceph是一款开源的分布式存储系统,具备高可用性、高扩展性与高性能等核心优势。它能统一提供块存储、文件存储和对象存储服务,广泛应用于云计算、大数据分析、企业级存储等场景。部署Ceph的核心目标是构建一个稳定、可灵活扩展的集群环境。
软件特点:

基本结构
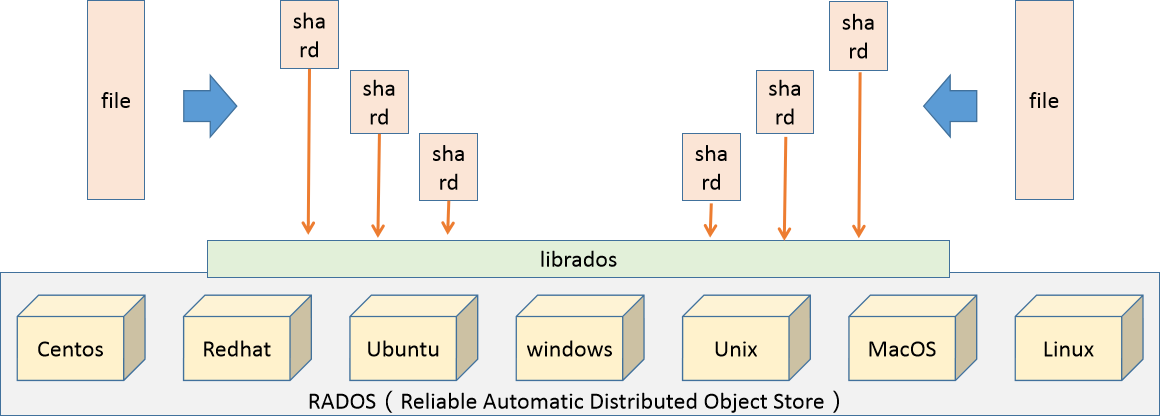
Ceph是一种多版本存储系统,它会将每个待管理的数据流(如一个文件)切分为一个或多个固定大小的对象(Object),并以对象为原子单位进行数据存取。
对象的底层存储服务由多个主机组成的存储集群提供,该集群被称为 RADOS(Reliable Automatic Distributed Object Store),即可靠、自动化、分布式对象存储系统。librados 是RADOS存储集群提供的API库,支持C、C++、Java、Python、Ruby和PHP等多种编程语言。
应用场景
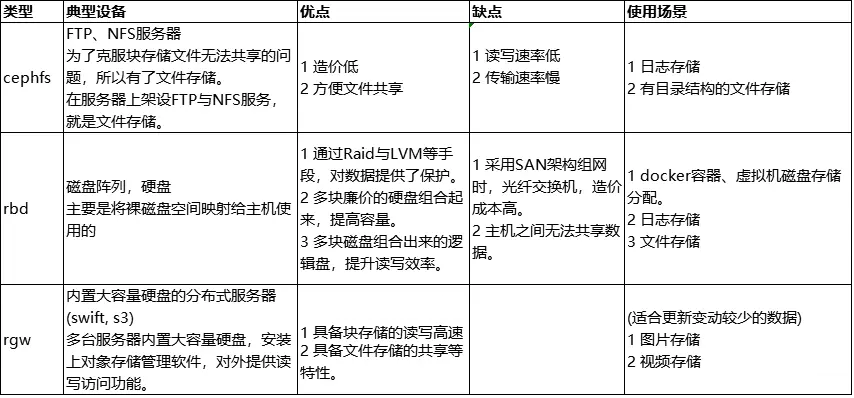
组件解析
无论您是想在云平台中使用Ceph对象存储或块设备服务,还是部署Ceph文件系统,所有Ceph存储集群的部署都始于Ceph节点配置、网络规划以及集群初始化。
一个Ceph存储集群至少需要以下组件:
- Ceph Monitor
- Ceph Manager
- Ceph OSD(对象存储守护进程)
若使用Ceph文件系统,则还需要 Ceph 元数据服务器(MDS)。

| 组件 | 说明 |
|---|---|
| Monitor(监视器) | 维护集群状态映射(包含Monitor、Manager、OSD、MDS拓扑及CRUSH算法配置等),相当于集群的“全局地图”;负责守护进程与客户端的身份合法性校验,防止未授权访问。基于Paxos协议实现多节点共识同步,确保集群状态一致。生产环境通常至少部署3个节点实现高可用,支持容忍1个节点故障。 |
| Manager(管理器) | 实时跟踪集群运行时指标与状态,涵盖存储利用率、IOPS/吞吐量、节点CPU/内存负载、PG健康状态等;提供Web可视化仪表板和REST API,支持运维人员图形化管控及自动化运维集成。基于轻量级Raft协议完成多节点状态同步,通常至少部署2个节点实现高可用,故障时备用节点可无缝接管。 |
| OSD(对象存储守护进程) | 集群的核心数据存储单元,每个OSD对应主机上的一块物理/逻辑磁盘;负责用户数据的写入、读取,同时处理数据副本复制、故障数据恢复、集群扩容/缩容时的数据再平衡等核心任务;定期向Monitor和Manager上报自身健康状态(如磁盘使用率、IO延迟、故障标识)。生产环境至少部署3个节点实现数据冗余,支持容忍1个节点故障不丢失数据。 |
| MDS(元数据服务器) | 专用于Ceph文件系统(CephFS)的组件,负责存储文件系统的元数据(包括文件名、目录结构、文件权限、修改时间等);将元数据与实际数据分离存储,使ls、find等POSIX文件系统操作直接调用元数据,避免对OSD存储集群造成额外负担,大幅提升CephFS响应效率。仅在部署CephFS时需要配置,对象存储(RGW)、块设备(RBD)场景无需部署。 |
| PG(Placement Groups,放置组) | 连接用户数据与OSD的逻辑中间层,无实体进程;一个PG会映射到一组OSD(主OSD+副本OSD),同一PG内的所有用户对象均存储在对应OSD组中。引入PG可大幅简化“对象-OSD”的映射复杂度,配合CRUSH算法实现数据均匀分布与快速定位;数据写入时,会先写入主OSD,再同步至副本OSD完成冗余。规划时建议每OSD对应100-200个PG,平衡集群性能与管理开销。 |
流程解读
综合效果图
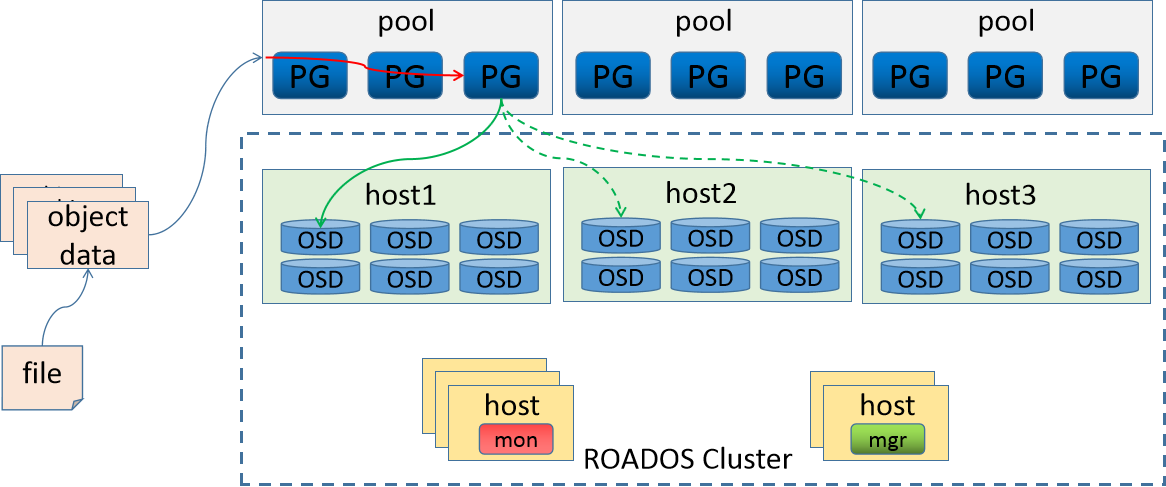
Ceph将数据作为对象存储在逻辑存储池中,主要包括两个映射步骤:
对象 → PG
通过哈希算法计算对象应归属的PG。PG → OSD
通过CRUSH算法决定该PG应存储在哪几个OSD上。CRUSH算法支持集群动态扩展、再平衡与恢复。
数据存储逻辑
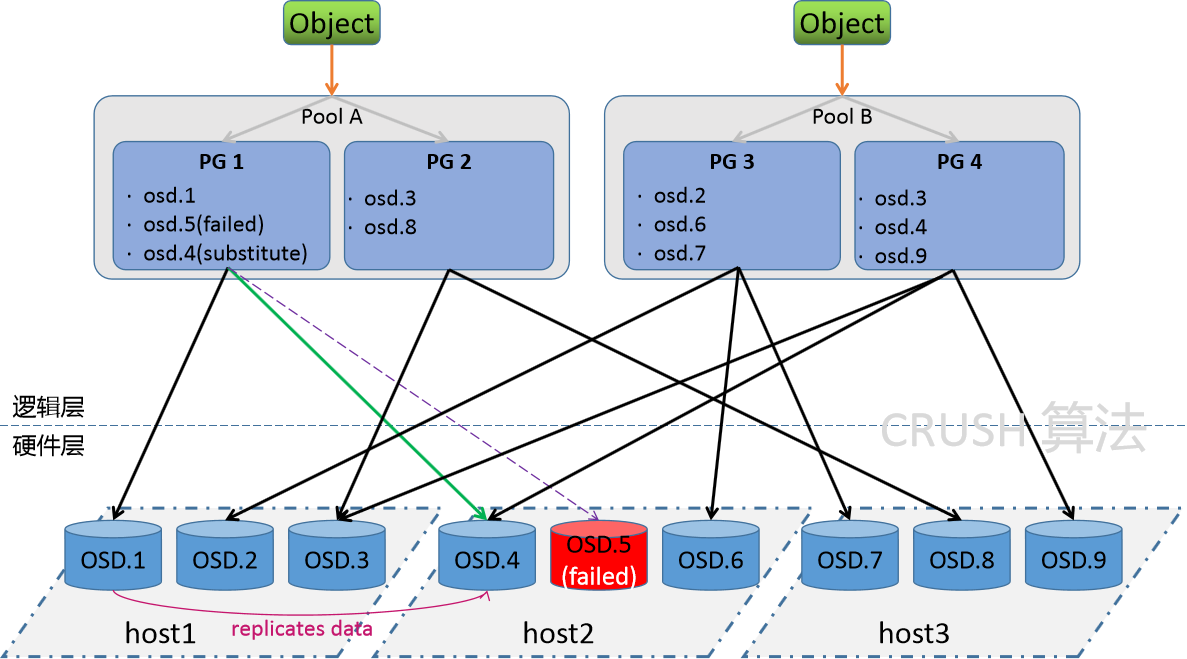
存储原理
存储过程说明
Ceph存储集群接收来自客户端的数据(无论通过块设备、对象存储、文件系统还是自定义librados实现),数据最终以RADOS对象形式存储,每个对象位于一个OSD上。
Ceph OSD守护进程负责在存储驱动器上执行读写和复制操作,其底层存储机制主要有两种:
- Filestore方式:每个RADOS对象作为单独文件存储在传统文件系统(通常为XFS)上。
- BlueStore方式:对象以类似数据库的整体方式存储,这是新版Ceph的默认存储方式。
注意:在Ceph中,每个文件都会被拆分为多个独立的object,再按上述逻辑持久化存储。
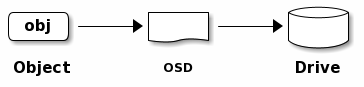
Ceph OSD守护进程将“数据”以对象形式存储在平面命名空间中,每个对象包含:
- 标识符:在内存中唯一标识对象
- 二进制数据:对象的实际内容
- 属性数据:由键值对组成的元数据,语义由Ceph客户端决定(例如CephFS用其存储文件所有者、创建时间等属性)
注意:对象ID在整个集群内唯一,不限于本地文件系统。

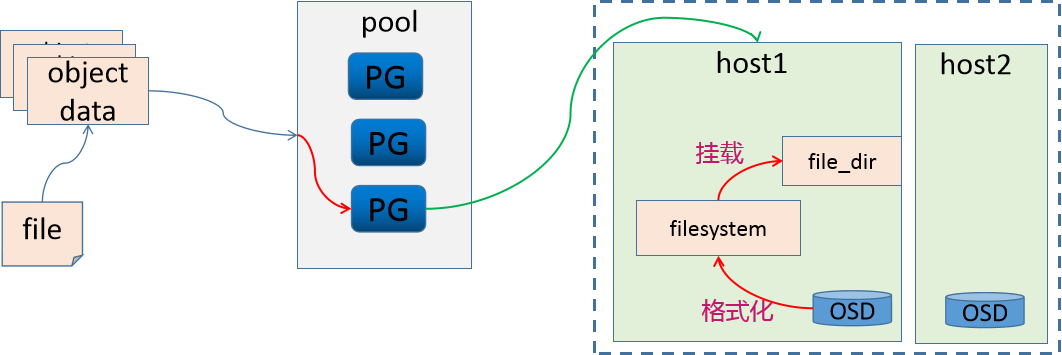
例如,存储一个16MB文件时,会先将其切分为多个4MB的object,通过哈希映射到对应PG,再经由CRUSH策略分布到不同主机的OSD上。
此时面临一个问题:OSD作为磁盘设备,应如何存储数据?
常见存储实现方式
- Filestore
将OSD格式化为文件系统(如XFS)并挂载到目录使用。此时每个object成为文件系统中的一个文件(或目录),OSD需维护object的属性信息。
由于文件系统元数据区仅能存储属主、权限等基本信息,Ceph会将额外元数据存入单独数据库(如LevelDB)中。
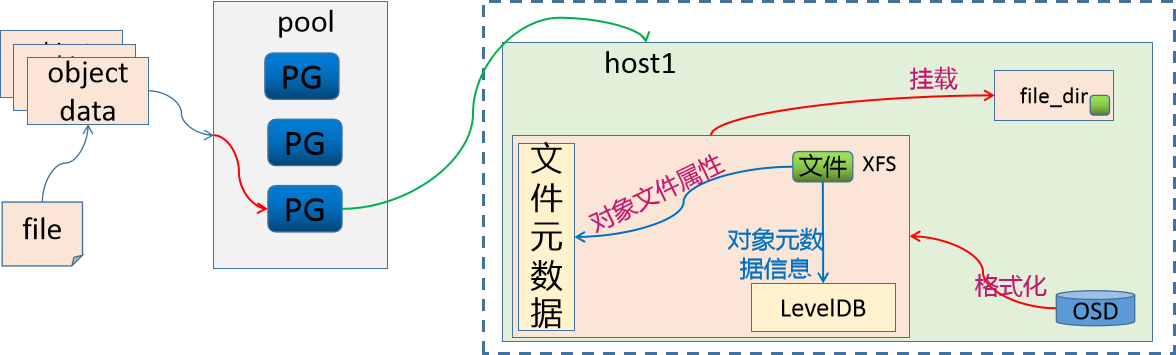
这种方式称为Filestore,因object需转为文件形式存储,在元数据读写效率上存在一定开销。
- BlueStore
在新版Ceph中,每个ceph-osd守护进程内部维护一个RocksDB数据库,用于存储object的元数据。RocksDB基于Ceph自研的BlueFS文件系统运行。
RocksDB + BlueFS 共同构成BlueStore存储机制,这也是当前Ceph默认的存储后端。
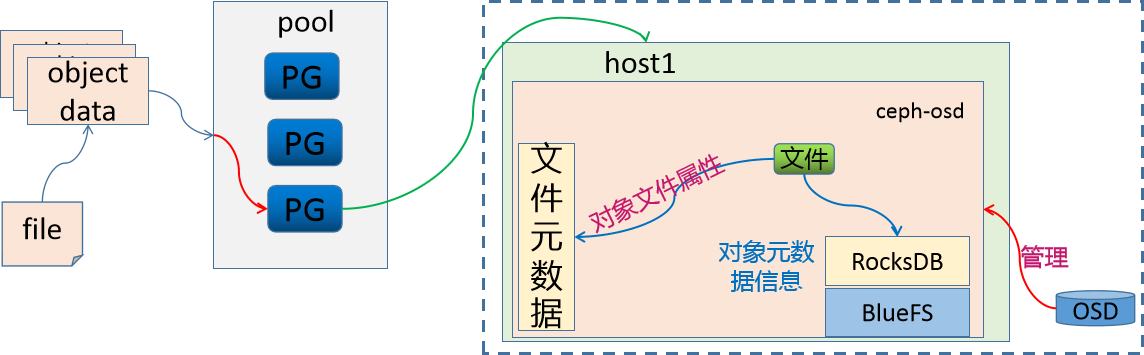
BlueStore直接管理裸设备,避免了文件系统层的开销,显著提升了读写性能与元数据管理效率。
集群部署
以下为Ceph集群部署的关键步骤摘要,具体细节请参考官方文档或完整部署指南。
环境概述
本次部署采用单节点Ceph集群架构,将Ceph所有核心组件集中部署于单一节点上,旨在快速搭建学习环境,重点掌握Ceph与Kubernetes的存储对接流程。此配置适用于学习验证、功能测试及开发调试场景,能够以最小资源开销实现全流程实践。请注意:该架构不具备高可用与容灾能力,不可用于生产环境;生产部署需采用多节点集群,以确保服务的可靠性与数据的安全性。
| 主机名 | 角色 | IP地址 |
|---|---|---|
| ceph.local | Ceph单节点集群(所有组件)使用centos-9 | 10.1.1.22 |
| K8s-master | K8s Master 节点 k8s 版本v1.27.x | 10.1.1.100 |
| K8s-node1 | K8s Node 节点 | 10.1.1.120 |
| K8s-node2 | K8s Node 节点 | 10.1.1.130 |
在ceph.local上准备三块盘
安装cephadm工具
根据不同操作系统选择安装方式,如CentOS使用curl下载,Debian/Ubuntu通过apt安装。
安装cephadm工具
CentOS/RHEL
1 | 下载cephadm |
Debian/Ubuntu
1 | wget -q -O- 'https://download.ceph.com/keys/release.asc' | gpg -o /etc/apt/keyrings/ceph.gpg --dearmor |
引导初始化集群
1 | cephadm bootstrap \ |
添加 Ceph(Squid 版本)仓库并安装ceph-common
1 | 添加Reef版本仓库 |
查看 Ceph 集群状态(后续操作示例)
1 | 查看集群健康状态 |
添加OSD
1 | ceph orch daemon add osd ceph.local:/dev/sdb |
查看OSD
1 | ceph orch ps --daemon_type osd |
查看集群状态
1 | ceph -s |
创建cephfs文件系统(用于k8s存储)
1 | # 创建元数据池和数据池 |
ceph-csi 驱动默认要求使用csi子卷组来存放 K8s PVC 对应的 CephFS 子卷,如果这个子卷组不存在,就会报 “subvolume group ‘csi’ does not exist” 错误,导致 PVC 创建失败。
用户管理
Ceph集群管理员可直接在集群内完成用户的创建、更新与删除操作。需注意:创建用户时,可能需要将生成的密钥分发至客户端,并添加到客户端的密钥环中,确保客户端能正常接入集群。
核心命令
列出集群所有用户:命令为
ceph auth list。- 用户标识格式:
TYPE.ID
例如:osd.0表示 OSD 类型的用户,其 ID 为 0;client.admin表示客户端类型的 admin 用户。
- 用户标识格式:
检索特定用户信息:可通过
ceph auth get TYPE.ID或ceph auth export TYPE.ID命令实现,前者直接输出用户详情,后者可导出用户密钥信息。列出特定用户密钥:命令为
ceph auth print-key TYPE.ID,仅输出目标用户的密钥字符串,适用于快速获取密钥的场景。
用户管理实践
常用命令解析
| 命令 | 用途 | 特点 |
|---|---|---|
ceph auth add | 创建用户并设置权限 | 生成密钥并添加指定 caps |
ceph auth get-or-create | 创建用户或获取现有用户信息 | 返回密钥文件格式的密钥信息 |
ceph auth get-or-create-key | 创建用户或获取现有用户密钥 | 仅返回密钥字符串 |
ceph auth import | 导入用户 | 从备份文件恢复用户 |
ceph auth caps | 修改用户权限 | 会覆盖现有 caps |
ceph auth del | 删除用户 | 彻底移除用户 |
权限配置要点:
- 典型用户至少需要对 Ceph Monitor 具有读取权限
- 对 Ceph OSD 通常需要读写权限
- 重要:OSD 权限应限制在特定存储池,否则用户将获得集群中所有存储池的访问权
修改权限时的注意事项:
使用 ceph auth caps 命令会完全覆盖用户现有权限。建议先通过 ceph auth get TYPE.ID 查看当前权限,再进行修改。
简单实践:完整用户操作流程
添加用户(创建普通用户)
先通过帮助命令了解auth模块的完整用法,再创建带权限限制的普通用户:
1 | # 查看auth命令帮助 |
验证新创建用户信息
1 | # 查看用户完整信息 |
修改用户权限
将client.testuser的MDS的权限添加:允许读 + 写(read+write),MGR添加读(read)权限,OSD权限增加至data_for_k8s和metadata_for_k8s池:
1 | # 修改权限 |
导出用户信息(备份/迁移)
可直接输出用户信息,或导出至文件保存(适用于备份或迁移到其他集群):
1 | # 直接输出导出信息 |
删除用户
删除无用用户,释放集群资源并保障安全:
1 | # 删除client.testuser |
导入用户(从备份恢复)
通过之前导出的密钥环文件,恢复已删除的用户:
1 | # 从testuser.file导入用户 |
特殊场景:get-or-create命令使用
该命令适用于“不确定用户是否存在”的场景,避免重复创建或漏创建:
1 | # 尝试创建已存在的用户client.testuser |
结果说明:若用户已存在,get-or-create仅返回信息;若不存在,则直接创建并返回配置,适合自动化脚本中的用户创建场景。
部署Ceph-csi
下载 ceph-csi 资源清单(在 K8s Master 节点执行)
1 | 克隆ceph-csi仓库(指定v3.11版本分支) |
查看认证用户信息:
1 | ceph auth get client.admin |
编辑资源配置清单
1 | cp examples/cephfs/secret.yaml /root/cephfs/ |
ceph-csi-config 是Ceph CSI(Container Storage Interface)插件 的核心配置资源,主要用于向 Kubernetes 集群中的 Ceph CSI 插件提供连接后端 Ceph 集群的关键信息,让 CSI 插件能够和 Ceph 集群建立通信,从而实现 Kubernetes 对 CephFS 存储的生命周期管理(比如创建 / 删除 CephFS 卷、挂载 / 卸载卷、管理 CephFS 子卷组等)。简单来说,它是 K8s 和 Ceph 集群之间的 “通信配置桥梁”。
1 | cp /root/ceph-csi/deploy/cephfs/kubernetes/csi-config-map.yaml /root/cephfs/ |
各配置项的注释说明
以下是移除的注释对应的配置项解释,按层级梳理:
1. 顶层配置(Ceph 集群连接基础)
| 配置项 | 说明 |
|---|---|
clusterID | 【必填】Ceph 集群的唯一标识;获取方式:在 Ceph 集群节点执行 ceph -s,输出中找 “id: xxx-81a1-40f6-97b7-xx” |
monitors | 【必填】Ceph Monitor 节点的地址列表;ceph-csi 通过这些地址连接 Ceph 集群 |
2. cephFS 子配置(CephFS 存储专属规则)
| 配置项 | 说明 |
|---|---|
subvolumeGroup | 【关键】指定 ceph-csi 创建子卷时使用的子卷组(对应提前创建的 csi 子卷组) |
kernelMountOptions | 内核挂载 CephFS 时的额外参数(比如 ro= 只读,默认空即可) |
netNamespaceFilePath | 网络命名空间文件路径;设置为空避免 “找不到网络命名空间” 的报错,非特殊网络场景留空是最佳实践 |
fuseMountOptions | FUSE 方式挂载 CephFS 的额外参数(默认空即可) |
3. readAffinity 子配置(读性能优化)
| 配置项 | 说明 |
|---|---|
enabled | 是否启用读亲和性;false= 关闭,适合单节点 / 小规模集群 |
crushLocationLabels | 用于读亲和性的 CRUSH 位置标签;启用时需配置(比如 ["host", "rack"]),关闭时留空 |
修改ceph-conf配置文件
1 | $ cp /root/ceph-csi/deploy/cephfs/ceph-conf.yaml /root/cephfs/ |
1 | 复制RBAC和provisioner配置 |
1 | cp /root/ceph-csi/examples/cephfs/storageclass.yaml /root/cephfs/ |
应用资源配置清单
1 | cd /root/cephfs/ |
验证:
1 | root@k8s-master:~# kubectl get -n cephfs secrets |
验证cephfs使用
创建pvc
1
2
3
4
5
6
7
8
9
10
11
12
13# pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: csi-cephfs-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
storageClassName: csi-cephfs-sc应用pvc:
kubectl apply -f pvc.yaml查看绑定信息
kubectl get pvc csi-cephfs-pvc或kubectl describe pvc csi-cephfs-pvc创建pods进行pvc绑定
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18# pod.yml
apiVersion: v1
kind: Pod
metadata:
name: csi-cephfs-demo-pod
spec:
containers:
- name: web-server
image: docker.io/library/nginx:latest
volumeMounts:
- name: mypvc
mountPath: /usr/share/nginx/html
volumes:
- name: mypvc
persistentVolumeClaim:
claimName: csi-cephfs-pvc
readOnly: false修改nginx 的首页信息
1
2kubectl exec -it csi-cephfs-demo-pod -- bash
echo $HOSTNAME > /usr/share/nginx/html/index.html访问nginx页面
1
2
3
4
5
6
7
8
9
10kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
csi-cephfs-demo-pod 1/1 Running 0 4d14h 172.17.220.118 k8s-node01.local <none> <none>
curl 172.17.220.118
csi-cephfs-demo-pod
在k8s-node01.local 查看挂着信息
mount |grep ceph
testuser@eb9728e2-ec47-11f0-aac5-000c29b88afc.k8s=/volumes/csi/csi-vol-58d8d81f-1a3a-494e-a87f-f86cae16c6d1/2b67bb5b-0ae9-435c-806a-883f8d92d90f on /var/lib/kubelet/plugins/kubernetes.io/csi/cephfs.csi.ceph.com/849761e041befc33136d68dc18a637394d7dc0bfdd2d199e61f38061d5765551/globalmount type ceph (rw,relatime,name=testuser,secret=<hidden>,acl,mon_addr=10.1.1.200:6789)
testuser@eb9728e2-ec47-11f0-aac5-000c29b88afc.k8s=/volumes/csi/csi-vol-58d8d81f-1a3a-494e-a87f-f86cae16c6d1/2b67bb5b-0ae9-435c-806a-883f8d92d90f on /var/lib/kubelet/pods/cf503833-3f10-436b-aa84-724cf2f9f282/volumes/kubernetes.io~csi/pvc-9580f87e-9c32-45f8-8fbf-107a08b092f2/mount type ceph (rw,relatime,name=testuser,secret=<hidden>,acl,mon_addr=10.1.1.200:6789,_netdev)













